During my thesis, I was working on state-of-the-art sound localization solutions. Indoor source localization is used in several applications. Here the focus was for behind-the-ear hearing devices. Bandwidth reduction in the data-transfer in the model was the main focus. Additionally the MAC number was improved and the knowledge distillation was done successfully for proof-of-concept.
PAPER PUBLICATION IWAENC-IEEE
"INVESTIGATION ON SYSTEM BANDWIDTH FOR DNN-BASED BINAURAL SOUND LOCALISATION FOR HEARING AIDS"
Promotor
Supervisors
dr.prof.ir. Nilesh Madhu
ir. Stijn Kindt
ing. Jasper Maes
ir. Siyuan Song
Data
The data used to train and test the solution were built out of datasets with male and female speakers reading sentences from the TIMIT and PTDB-TUG datasets. Data was preprocessed with generated binaural room impulse responses and noise. Pyroomacoustics was the main library for the room impulse response generation. To take the head reflections into consideration, the head-related transfer function was used. This simulated the shadow effect of the head and shoulders on the audio signals.
Centralized model
The network architecture was inherited from previous research. This model predicts the direction of arrival (DOA) with short-term Fourrier transform (STFT) amplitude and phase as input. Here the input signals from each microphone (channels) are send through a lossy LC3+ codec with a minimal bit rate of 16 kbps to the central processor. Since the all the data is available on the central unit now, convolutional layers can combine channels to gain information from intra- and inter-ear microphones per frequency band. Then, broadband embedded features are created in the fully connected layer. These features are fed into the LSTM layer to gain temporal context. Lastly, a final output fully connected layer provides the classification in several DOA sector estimates per source per time sequence.

Centralized network architecture for sound source localization with lossy LC3+ codec on input signals.
Co-operative model
Similar to the centralised model, the architecture has one main difference. In this model, computations are executed partially in the on-ear device. Herefore, the sent data consists of broadband embedded features instead of encoded raw audio data. Consequently, only inter-ear information sharing is possible in the form of broadband embedded features. Here the number of microphones have no influence in the used bandwidth for data transmission.

Compression
For compressing the model, several approaches were tested. Beginning with, quantization, adjusting time resolution, frequency resolution, feature layer and input amplitude normalisation. The results of these approaches are depicted in the figure below. For more information I refer to the extended abstract or master's dissertation.
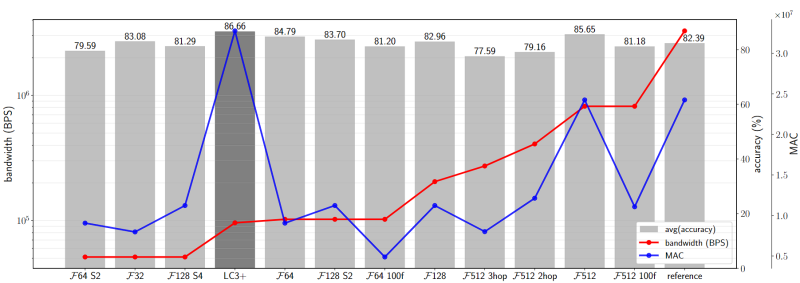
Knowledge distillation
Battery life is essential to have a user-friendly and sustainable device. This could be achieved by adjusting the model and making it smaller. In order to achieve similar performance, knowledge distillation was used. Hereby, the student-teacher structure was implemented during training where the student is the smaller model and the teacher the bigger. The loss function of the student was adjusted with loss from the teacher network.

Model expansion
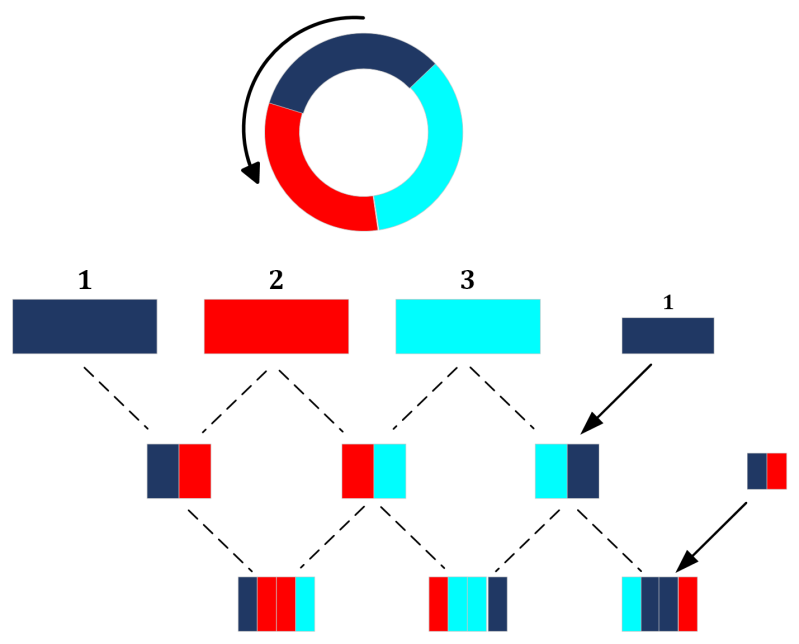
Knowledge distillation works best on superior teachers. As the size does not matter here, expension techniques were tested. One of the tested techniques involved circular padding to make extra intra-ear convolutions possible. By using extra convolutions, better intra-ear broandband features can be made out of the narrow-band features, before sharing data.


The violin plot depicts the average accuracies for the testing conditions given in the legend below. For the name conventions the following is used, e.g. 3C128 FC1024 G. 3 convulutions with 128 filters, a fully connected layer with 1024 nodes and a GRU as temporal layer.
Maak jouw eigen website met JouwWeb